Bedrockのモデルを試す
まずはBedrockを触る際に必要となる知識の説明をしていきます。
プロンプトとは
AIの分野においてプロンプトは、ユーザーがAIに対して行う入力という意味合いで使われています。
これらの大規模言語モデルを使用して十分な性能を発揮するにはプロンプトを工夫する必要があります。
また、モデルを使用する際には実際にかかる料金を知っておく必要があります。それでは実際に幾つかのモデルを触ってみましょう。
実際にみてみる
AWSにアクセスしてください。
アクセスできたら、
Amazon Bedrockのプレイグラウンド にアクセスしてください。
右上のリージョンはオレゴン、モデルはClaude 3 haikuを選択してください。

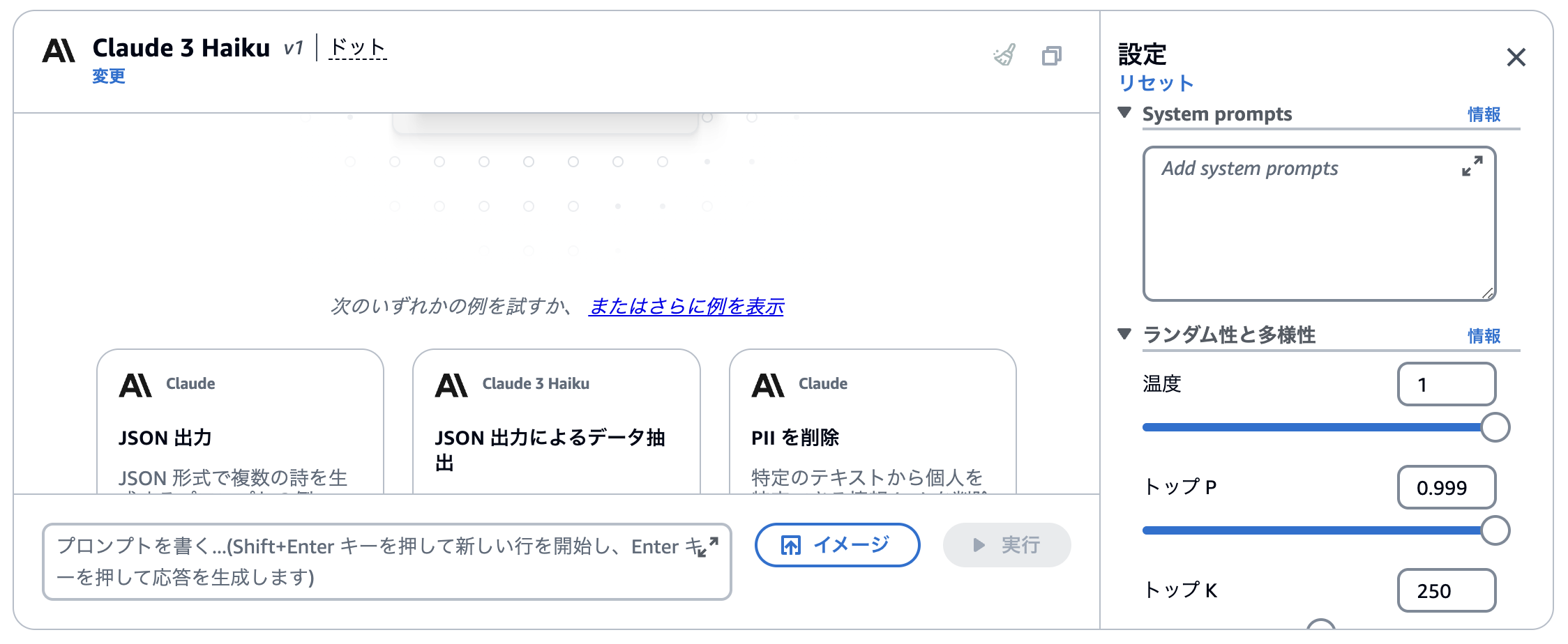
このような表示が出てくると思います。
ここはBedrockのプレイグラウンドで、AWSで扱うことのできるさまざまなモデルを実際に試すことができます。
右側にある引数の説明をしていきます。
どれもランダム性に関わる値で大きくなるほどランダムな文章が生成されます。
比較モードをonにして右側の+ボタンを押し、モデルを選択すると同時に複数のモデルを比較することができます。
また、変更を押すとモデルを変更することができます。
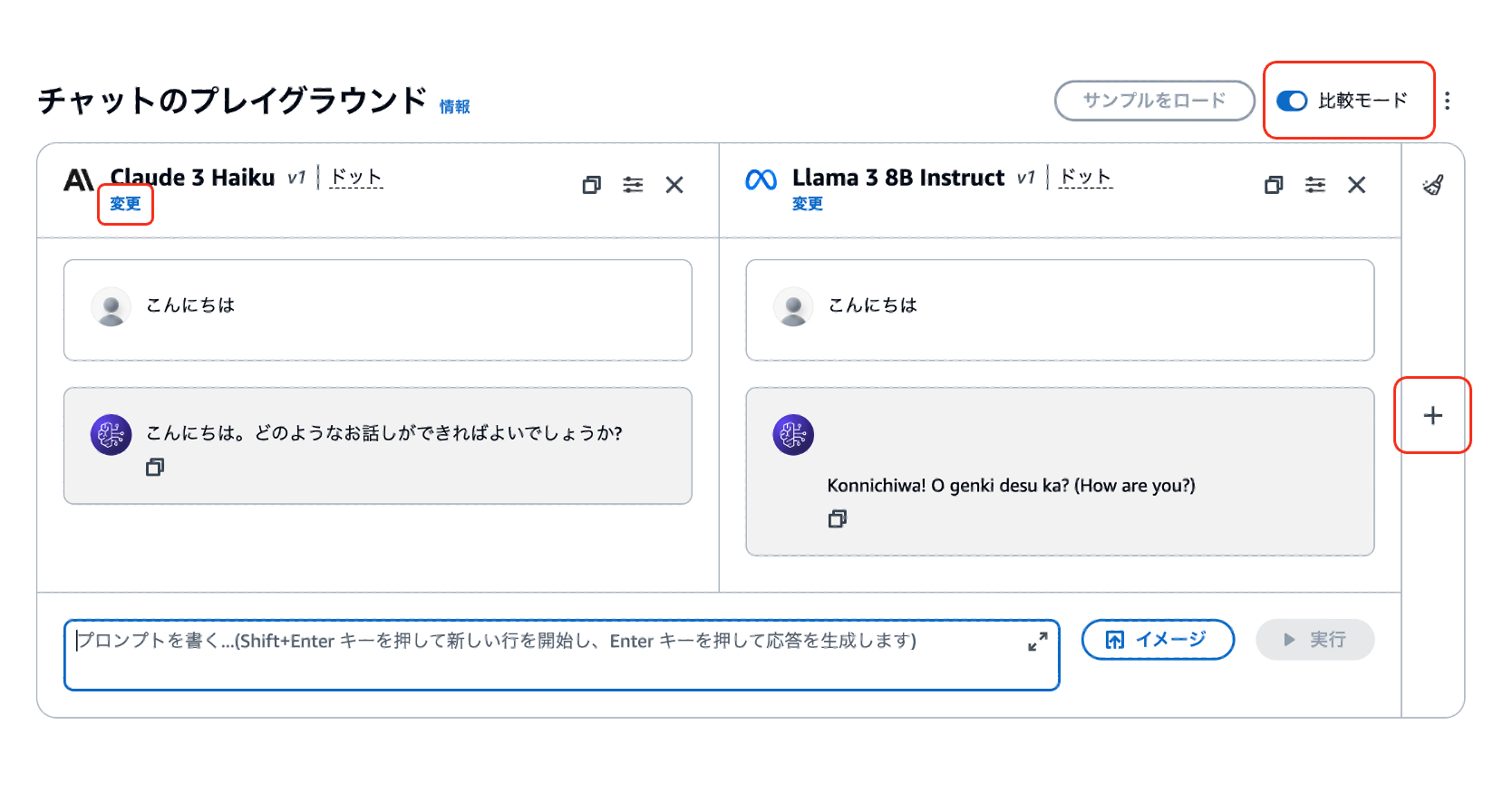
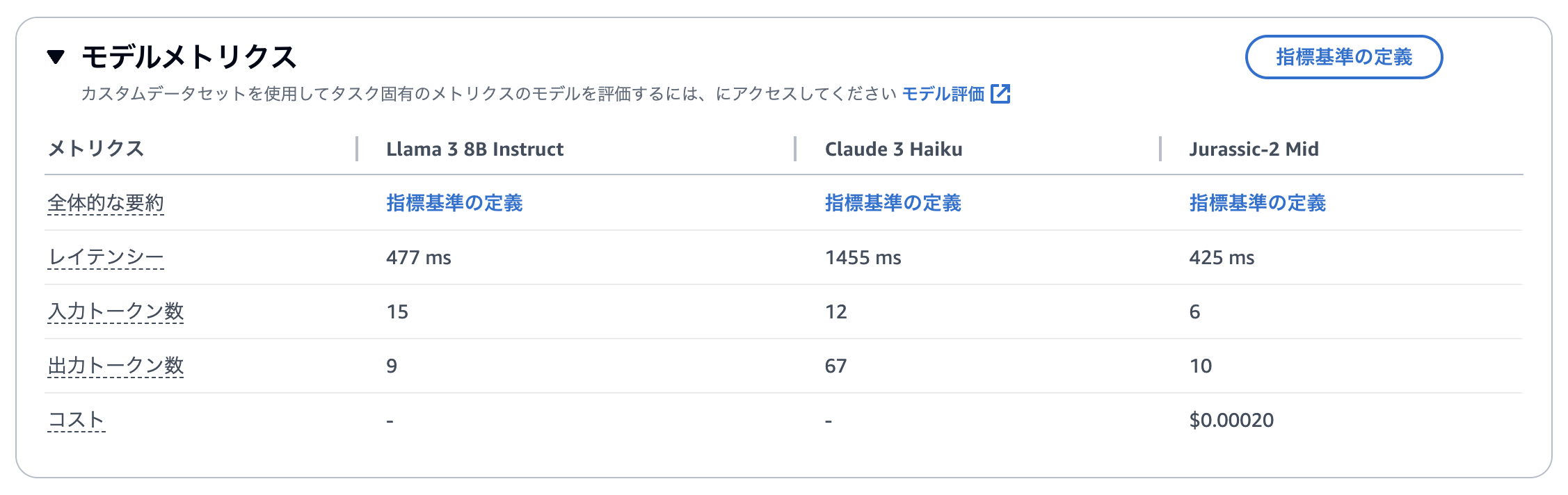
それでは、比較モードをonにして+ボタンを押し、Anthropic社のClaude 3 HaikuとAI21 Labs社のJurassic-2 MidとMeta社のLlama 3 8B Instructを選択してみましょう。
できたら実際に何か入力してみてください。(3分)
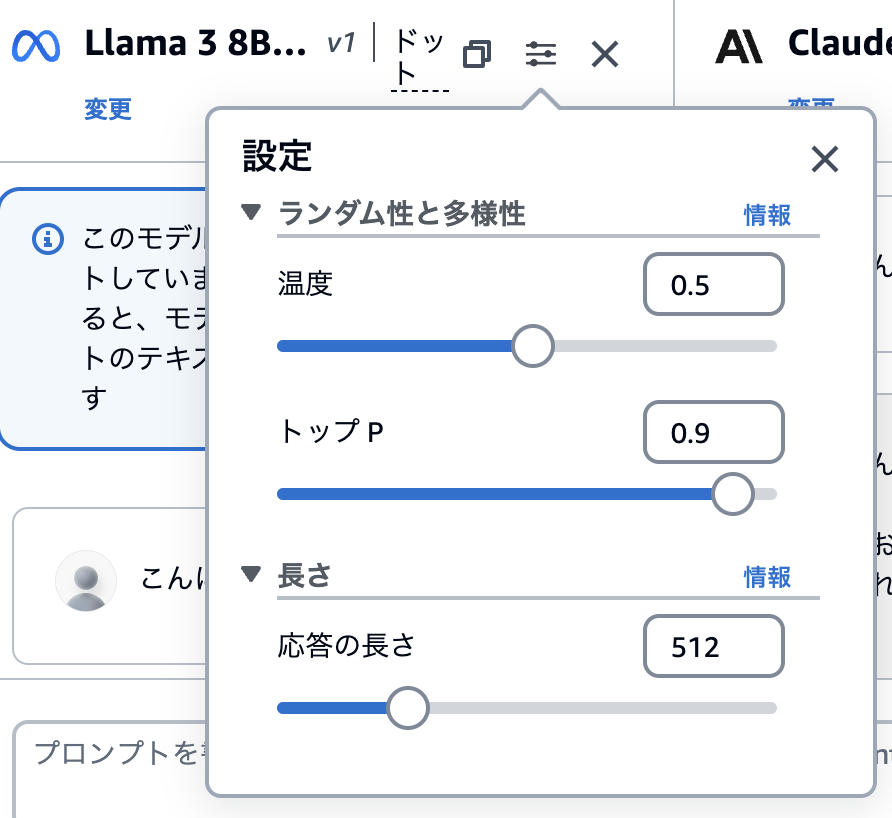
したの画像の部分をクリックしてパラメータも変化させてみて下さい。
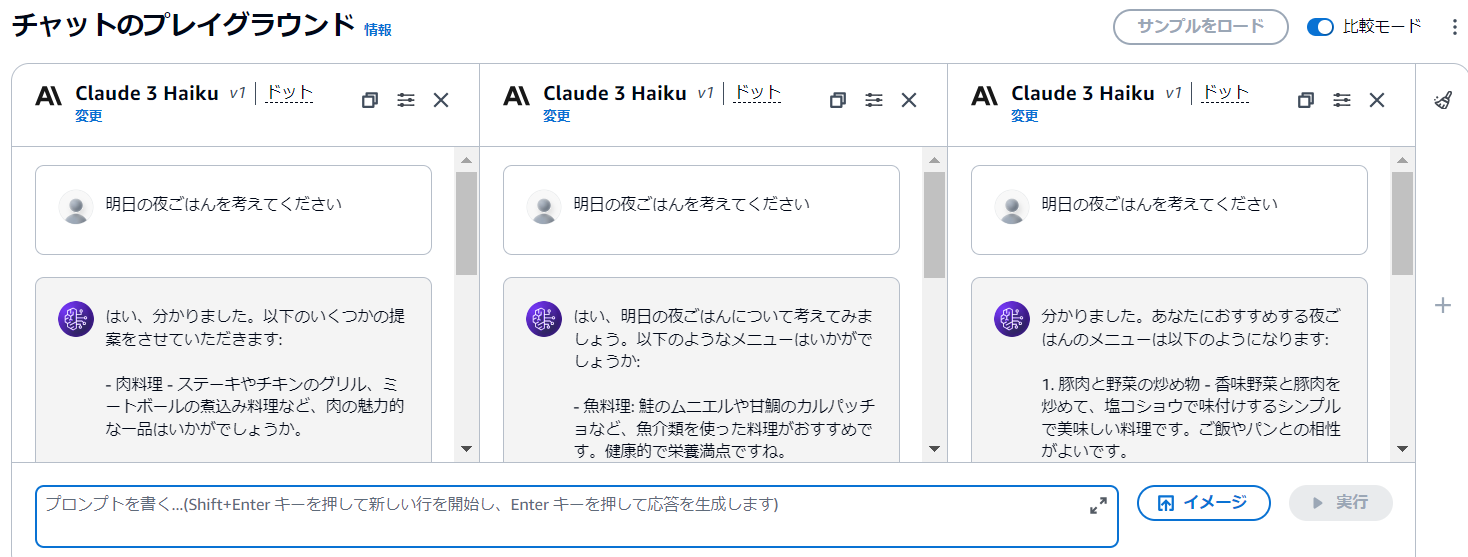
画面下部にリクエストに関する情報が出てくるかと思います。
よくあるパラメータの解説
下の画像のように画面のこの部分をクリックすると設定を変更することができます。実際にAPIにリクエストを送信する時もこのようなパラメータを設定することができます。
設定項目はモデルによって変わります。ここではよくある引数についての簡単な解説をします。
temperature
モデルが可能性の低いトークンを出力する確率を調整するパラメータ。値が大きいほど出力はランダムになります (そして通常はクリエイティブになります)。また、それに伴い正確性が下がります。データ抽出や真実の Q&A など、ほとんどの事実に基づくユースケースでは、
temperature
0 が最適です。
この値が大きくなるほど生成される値は以下のようにランダム性が増していきます。
値は以下のように変化します。
temperature: 0.01
昔々あるところに、おじいさんとおばあさんが住んでいた。 昔は
昔々あるところに、おじいさんとおばあさんが住んでいた。 昔は
昔々あるところに、おじいさんとおばあさんが住んでいた。 昔は
temperature: 1.0
昔々あるところに、おじいさんとおばあさんが住んでいたという光景は忘れられ
昔々あるところに、おじいさんとおばあさんが集まって、この歌を
昔々あるところに、おじいさんとおばあさんの葬儀があると聞いたときは
temperature: 2.0
昔々あるところに、おじいさんとわたしの家から遠くの海を見る景色
昔々あるところに、おじいさんとおばさんたちがいて(その人が昔の
昔々あるところに、おじいさんと私の家族の墓が出来ているそうです。今
temperature: 3.0
昔々あるところに、おじいさんと一丸になり手土産もゲットしたりでき
昔々あるところに、おじいさんと年収1000組くらいのお婆さのお
昔々あるところに、おじいさんと子どもたちが住むおうちに子どもが入り住みつけ
temperature: 4.0
昔々あるところに、おじいさんとおば婆がおりたらきもしますっと
昔々あるところに、おじいさんと小学生3人が大勢現れ、 でも
昔々あるところに、おじいさんとおば婆も現れた。 また、「自分の
temperature: 5.0
昔々あるところに、おじいさんと弟夫婦や祖母などの親子のような顔して
昔々あるところに、おじいさんとご年男の方はいなかったのかもと思う。
昔々あるところに、おじいさんとおばぁは遊び相手ができてきた・そう
また、temperatureの値ごとの確率の分布は以下のようになっています。
| index | temperature | 1位 | 2位 | 3位 | 4位 | 5位 |
| 0 | 0.01 | おば (100.00%) | アミン (0.00%) | 総司令官 (0.00%) | ワシントン州 (0.00%) | 同書 (0.00%) |
| 1 | 1.0 | おば (93.63%) | 娘 (0.45%) | おじさん (0.42%) | 、 (0.35%) | 老人 (0.31%) |
| 2 | 2.0 | おば (36.70%) | 娘 (2.54%) | おじさん (2.47%) | 、 (2.25%) | 老人 (2.10%) |
| 3 | 3.0 | おば (16.13%) | 娘 (2.72%) | おじさん (2.67%) | 、 (2.51%) | 老人 (2.40%) |
| 4 | 4.0 | おば (9.93%) | 娘 (2.61%) | おじさん (2.58%) | 、 (2.46%) | 老人 (2.38%) |
| 5 | 5.0 | おば (7.31%) | 娘 (2.51%) | おじさん (2.48%) | 、 (2.39%) | 老人 (2.33%) |
引用: https://qiita.com/suzuki_sh/items/8e449d231bb2f09a510c
top-p
確率の合計の閾値です。
top-pを0.1にすると
上の表でtemperatureが5.0の時を例にすると、おば (7.31%)+娘 (2.51%)+おじさん (2.48%)の確率を足した時に0.1を超えるのでこの3つが選択肢になります。
top-p=1とすると、全ての単語が選択肢として含まれます。
出典: https://note.com/pal7/n/n24d9e6670159
top-k
確率の高い単語上位何個を選択肢に含めるかの引数です。
停止シーケンス
ここで設定した文字や単語が出力されたら文章の生成を終了します。
“。”を設定すれば”今日は暑いですね。”のように句点が生成されたタイミングで文章の生成を終了します。
実践:プロンプトを考えてみよう
それでは実際に以下の2つの課題に対してプロンプトを考えてみましょう。
この時、パラメータを調整して変化を見つつ、生成時のトークン数や料金に注目してみましょう。
また、下に書いてあるプロンプトのコツも参考にしてみてください。
課題1:データ抽出
以下の名前を苗字と名前で分割し、json形式に変換して下さい。
制約:期待する結果に書かれている形式で生成させて下さい。
名前リスト(生成AIに考えてもらいました)
山田明里
佐藤隆
鈴木理沙
田中洋
伊藤美咲
高橋健二
小林桜
中村浩二
渡辺直美
加藤信二
期待する結果
[
{
"姓": "山田",
"名": "明里"
},
{
"姓": "佐藤",
"名": "隆"
},
{
"姓": "鈴木",
"名": "理沙"
},
{
"姓": "田中",
"名": "洋"
},
{
"姓": "伊藤",
"名": "美咲"
},
{
"姓": "高橋",
"名": "健二"
},
{
"姓": "小林",
"名": "桜"
},
{
"姓": "中村",
"名": "浩二"
},
{
"姓": "渡辺",
"名": "直美"
},
{
"姓": "加藤",
"名": "信二"
}
]
課題2:クリエイティブ
あなたを表すキャッチコピーを一言で考えてもらってください。
例:一生夏休み。
制約:一文で考えてもらってください。最後には句点を含めてください。
プロンプトのコツ
Open aiの公開しているプロンプトのベストプラクティスをいくつか紹介します。
Open aiの公開しているコツをGoogle翻訳によって日本語化したものです。
あくまでGPTを利用する際のコツなので全てのアドバイスが有用ではない可能性があることをご留意ください。
例を通して希望の出力形式を明確にする
例
以下のテキストで言及されている重要なエンティティを抽出します。最初にすべての会社名を抽出し、次にすべての人物名を抽出し、次にコンテンツに適合する特定のトピックを抽出し、最後に一般的な包括的なテーマを抽出します
。 望ましい形式:
会社名: <comma_dependent_list_of_company_names>
人物名: -||-
特定のトピック: -||-
一般テーマ: -||-
テキスト: {text}希望するコンテキスト、結果、長さ、形式、スタイルなどについて、具体的かつ説明的かつできるだけ詳細に記載しましょう。
例
{有名な詩人} のスタイルで、最近の DALL-E 製品の発売 (DALL-E はテキストから画像への ML モデル) に焦点を当て、OpenAI についての感動的な短い詩を書いて。
「ふわふわした」不正確な説明を減らす
例
この製品について説明するには、3 ~ 5 文の段落を使用してください。
何をしてはいけないかを言うのではなく、何をすべきかを言う
効果が低い例
以下はエージェントと顧客の間の会話です。ユーザー名やパスワードを尋ねないでください。繰り返さないでください。
顧客: アカウントにログインできません。
エージェント:例
以下はエージェントと顧客の間の会話です。エージェントは問題の診断と解決策の提案を試みますが、PII に関連する質問は控えます。ユーザー名やパスワードなどの PII を要求する代わりに、ユーザーにヘルプ記事 www.samplewebsite.com/help/faq を参照するよう案内してください。
お客様: アカウントにログインできません。
エージェント:引用:Best practices for prompt engineering with the OpenAI API
他にも色々あるので読んでみてください
プロンプト例
プロンプトエンジニアリング戦略