目次
NoSQLとは
AIに聞いてみた
NoSQLとは
NoSQLは、従来のリレーショナルデータベース(RDBMS)とは異なる、非リレーショナルなデータベース管理システムの総称です。
- RDBMS以外の DBMS (データベース管理システム: D ata B ase M anagement S ystem)を NoSQL と呼ぶ
-
RDBには
カラムの追加に対して柔軟性がない
- テーブル設計が必要
- 各カラム(列)の型が厳密に決まっている
- データ量に比例して処理時間も増加していく
- NoSQLを使用することで、膨大な量のデータを処理することができるようになる
NoSQLの特徴
AI君再度登場
NoSQLの特徴
NoSQLの主な特徴は以下のようなことが挙げられます
1. スキーマレス
- NoSQLデータベースは事前にデータ構造を定義する必要がなく、フレキシブルなデータモデルを採用しています。これにより、データ構造の変更が容易になります。
2. 水平スケーラビリティ
- NoSQLでは、データを複数のサーバーに分散して格納するため、データ量の増大に合わせてシステムを柔軟に拡張できます。
3. 高可用性
- NoSQLでは、データの複製や分散配置により、単一障害点が発生しにくく、高い可用性を実現できます。
4. 高スループット
- NoSQLは単純なデータモデルを採用しているため、大量のデータを高速に処理できます。
5. CAP定理への対応
- NoSQLでは、整合性よりも可用性とパーティション耐性を重視した設計が可能です。
6.柔軟なクエリ
- RDBMSのようなSQL言語による複雑なクエリは必要とせず、キーバリューペア、ドキュメント指向、列指向といったデータモデルに合わせたクエリ方式を採用しています。
NoSQLのメリット
-
拡張性
- 水平スケーリング(マシンの台数を増やすスケーリング方法)に適しているため、あとからサーバの台数を増やしやすい
- RBDMSは主に垂直スケーリング(マシンのスペックを上げるスケーリング方法)で対応する
-
高速性
- 大量のデータの処理を捌くのが得意
- RDBはデータ量が増えるほど、処理時間も増加していく
-
柔軟性
- テーブルの構造を厳密に指定せず、そのままの形で拡張可能
-
分散処理
- 複数のノード(サーバ)に処理を分散することができる
-
高可用性
- 複数ノード運用に適しているため、マルチゾーンの構成にしやすい
- そのため耐障害性が高い
垂直スケーリングと水平スケーリング
垂直スケーリング
水平スケーリング
| 垂直スケーリング | 水平スケーリング | |
|---|---|---|
| 対応方法 | サーバのスペックアップ | サーバの台数増加 |
| 対応難易度 | 難しい | (設計次第で)容易 |
| 上限 | あり | なし(ただし無限には増やせない) |
| 設計難易度 | 低い | 高い |
NoSQLのデメリット
-
RDBで使える一部機能が使えない
- 後述のKVSやドキュメント指向型では集計クエリやソートが使えない
-
一部のモデルでは
トランザクション
が使えない
- 処理中にシステムがダウンすると、中途半端な状態になってしまう
- 同時並行で処理が実行された場合、整合性が取れなくなる可能性がある
-
命名規則などを決めないと闇鍋になる
- 何でも入るからと言って、命名規則なしにデータを入れるとデータの管理や検索が大変
-
トラブルシューティングに技術とシステムに対するドメイン知識が必要
- RDBの用に厳密なスキーマ定義などが決められているわけではないので、システムに合わせた対策が必要
- 要件定義(ユースケース)をはっきりさせてから設計しなくてはいけない

NoSQLの種類と具体例
ドキュメント指向型
- ドキュメントでデータを管理するNoSQL
- XML や JSON などの形でデータを保存することができる
- 後述の MongoDB にはレプリケーション機能があるので、耐障害性が高い
- ただし、 SQLが書けなかったり 、 トランザクションがない (データの一貫性が確保できない)などのデメリットもある
カラム指向型(ワイドカラム)
-
リレーション型が「行」ごとでデータを管理するのに対し、カラム指向型では
「列」単位
でデータを管理する
- 1つのキーに対して複数のカラムを作る
- RDSと違い、データが無かったりしても良いし、カラムごとの型指定もない
- 圧縮や分散処理に向いている
グラフ
- データを グラフ (ノード、エッジ、プロパティの3要素で構成される)で管理する
- 目的のデータを検索するのは得意だが、全体から絞り込みをするなどの検索方法は苦手
キーバリュー(KVS)
-
データと一緒にキーを保存する形式
- Pythonのdict型が近い
- IoTセンサーのデータ記録や株価・為替データの管理などに向いている
-
キーバリュー型の枠組みの中に、時系列型がある
- キー(時間)
- バリュー(データ)
階層型
- 親ノードと子ノードを使ってツリーでデータを管理する
- ルートがグラフ型より限定されるため検索は非常に高速だが、柔軟性や拡張性に欠ける
一部メインフレームで使われているため、めったに使われることはない(自分も見たことはない)
Amazon DynamoDB
Amazon DynamoDBとは

Amazon DynamoDB は、key-value およびドキュメントデータモデルをサポートする NoSQL データベースです。開発者は、DynamoDB を使用して小規模から開始してグローバルまで拡張できる最新のサーバーレスアプリケーションを構築して数ペタバイトのデータや 1 秒あたり数千万の読み込みおよび書き込みリクエストをサポートすることができます。DynamoDB は、従来のリレーショナルデータベースであれば高い負荷を生じさせていた高パフォーマンスのインターネット規模のアプリケーションを実行するように設計されています。
https://aws.amazon.com/jp/dynamodb/features/
- KVS およびドキュメント型をサポートするNoSQL
- スケーリングが容易なため、小規模~大規模まであらゆる規模のアプリケーションに対応する
以下はAWSのチュートリアルで使われているサンプル
用語
-
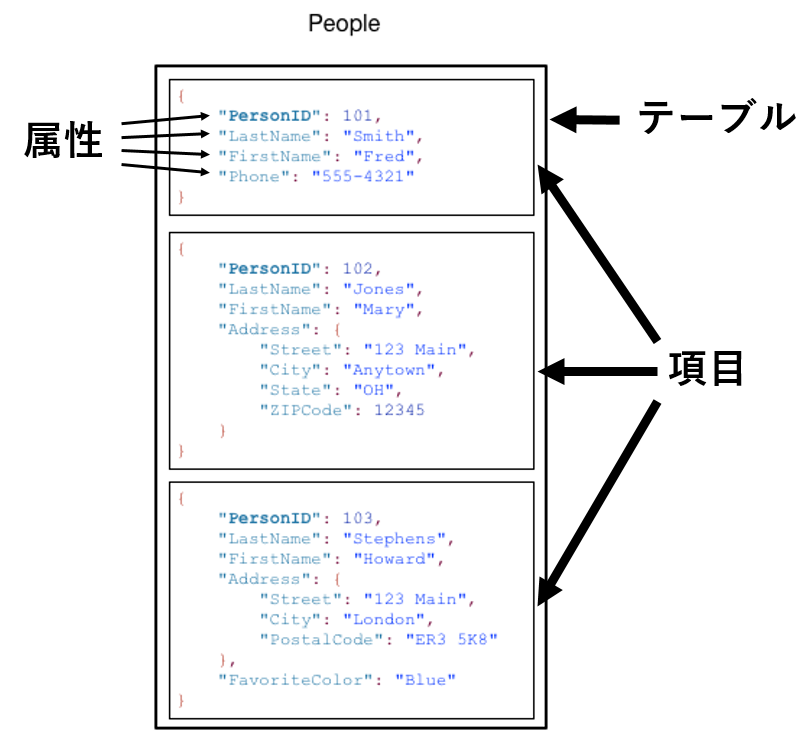
テーブル
- データの集まり
-
項目
- 1つのデータ(キー+バリューの集合)
- プライマリーキーが設定される
-
属性
- キー+バリューの1つの組み合わせ
- データの最小単位
-
プライマリーキー
-
パーティションキー
- 1つの属性で構成されるプライマリーキー
- テーブルの中で、必ず一意の値でなければいけない
-
パーティションキー
と
ソートキー
(
複合プライマリーキー
)
-
2つの属性で構成されたプライマリーキー
- 2つより多くは指定できない
-
1つ目の要素をパーティションキー、2つ目をソートキーと呼ぶ
- Atrist:パーティションキー
- SongTitle:ソートキー
- パーティションキーは重複しても良いが、パーティションキーとソートキーの組み合わせが必ず一意でなければ行けない
-
2つの属性で構成されたプライマリーキー
-
パーティションキー

答え
同じアーティストが同じタイトルで楽曲を出した場合
-
セカンダリインデックス
- パーティションキーやソートキーに加え、 代替キー を用いて検索できる機能
-
DynamoDBでは以下の2種類をサポート
-
グローバルセカンダリインデックス
- 今あるテーブルから、パーティションキーとソートキーを新たに作成してインデックスを作成する
- 1つのテーブルに付き、 20個まで 作成可能
-
ローカルセカンダリインデックス
- ソートキーのみ新たに設定したインデックス
- テーブル作成時のみ作成可能
- 1テーブルあたり 5個 まで
-
グローバルセカンダリインデックス
テーブルからのデータの読み込み
DynamoDBでは以下のオペレーションをサポートしている。
-
GetItem
- プライマリーキーを使用して、単一項目を取り出す
- データに直接アクセスするため、最も効率的にデータにアクセスできる
-
Query
- 特定のパーティションキーがあるすべての項目を取り出す
-
Scan
- 指定されたテーブルで、すべての項目を取り出す
- 大量のリソースを消費するので、使用は必要最低限に留めること
※ソートキーだけで検索することはできないので、検索したい場合はインデックスを作成する