機械学習モデル
大きく分けて2通り存在する
- 教師あり学習(supervised learning)
- 教師なし学習(unsupervised learning)
基本的な機械学習モデルについてだけ、頭に入れておきましょう
今回は教師ありのみ。いずれにしても、データに合ったモデルを心がけること
教師あり学習の手法
単回帰モデル
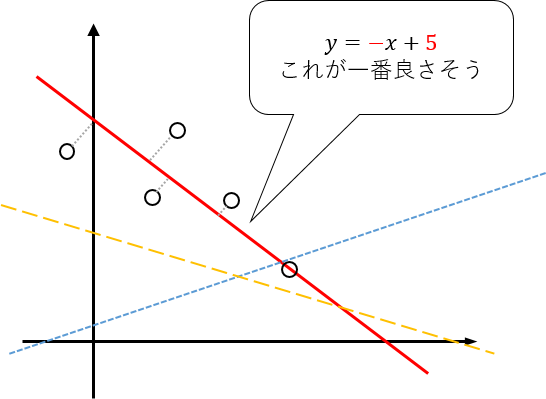
のような関係でフィッティングするモデル
最小二乗法
フィッティング方法は色々あるが、最も一般的なのは誤差の二乗を最小化する
- 二乗する一つの理由は、符号を無視して距離のみを考慮したいため
単純な単回帰分析の最小二乗法は、 について偏微分係数が になるときに最小(単純な二次関数)
よって、解析的に( で)解ける。後述するが、ほとんどのモデルや深層学習はそうはいかない
重回帰モデル
単回帰分析を自然に拡張したもの
線形な関数を直線、平面、超平面と拡張としても単回帰と同じようにして解析的に計算可能
次元の場合:
過学習を防ぐために、 式に正則化項を追加した以下のモデルがよく使われる。
- リッジ回帰(Ridge)
- ラッソ回帰(Lasso)
どのくらい関数を曲げてよいか、人間がコントロールできるパラメータがある、ということ。
メリット
-
結果を分析することが可能である。
-
単純に特徴量の線形結合で表されるため、重みの大きさがそのまま重要度と取れる。
-
ビジネス上必要な説明が比較的容易。
- 多重共線性の考慮が必要
-
ビジネス上必要な説明が比較的容易。
- 計算が単純ゆえに解析しやすい。
-
単純に特徴量の線形結合で表されるため、重みの大きさがそのまま重要度と取れる。
デメリット
-
線形ではない、複雑なデータでは表現力が足りないことがある。
- 現実のデータは入力に対して複雑なデータである場合が多い
- 線形モデルで扱うには、線形分離しやすいよう前処理を加える必要がある。
その他のバリエーション
-
多項式回帰
- 次多項式で回帰
-
ロジスティック回帰
- 確率を出力
-
SVM・ソフトマージンSVM
- 純粋に誤差の最小化では無く、クラス間の余白(mergin)で最適化
- 単層パーセプトロン
決定木
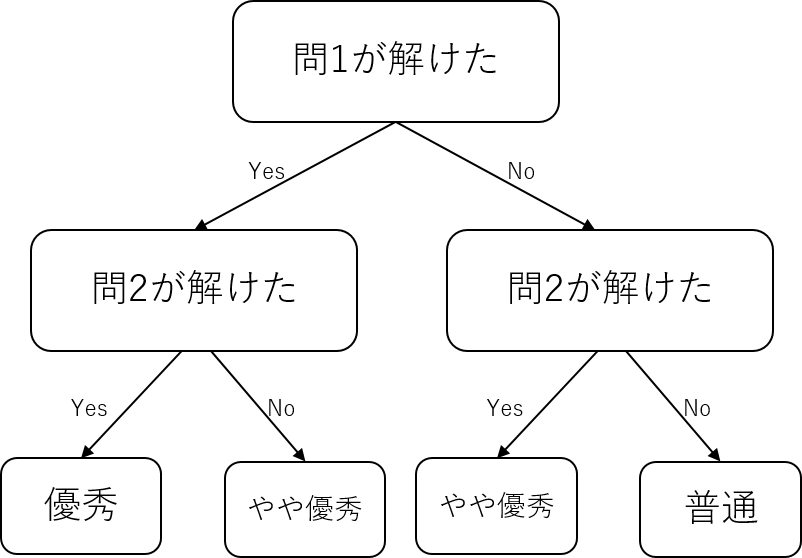
ある閾値で分岐する木構造で分類するモデル
- 工夫すれば回帰も出来る(回帰木)
- CART などの分割アルゴリズムによって、分割ルールを作成
-
ランダムフォレスト,XGBoost,LightGBM,CatBoostなど、決定木をベースとして拡張した手法が有名- 決定木を複数組み合わせて複雑な識別境界の学習を可能としている
メリット
-
解釈がしやすい
- それぞれはどういう条件でデータを分けるか?という分割ルールで構成されているため、解釈が容易
-
テーブルデータに対して使いやすい
-
NaNはNaNとして理解するため、データの欠損を埋めたりデータを他の特徴量と合わせてスケールする必要がない
-
デメリット
-
複雑な予測が単純な決定木モデルだと出来ない
-
先述した
ランダムフォレスト,XGBoost,LightGBM,CatBoostなどは解決している
-
先述した
-
決定木がベースなため、深層学習と比較すると目的に沿った構造を作るのが困難
- 音声やセマンティックセグメンテーションなど
ニューラルネットワーク
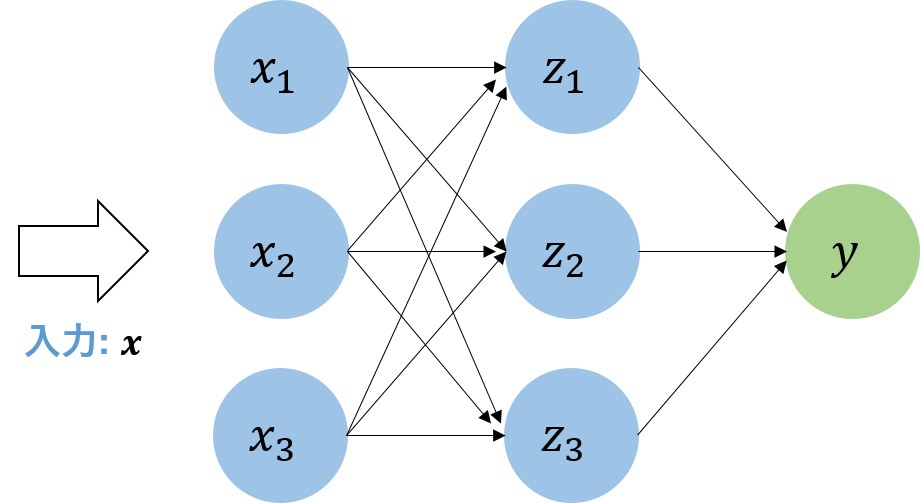
一部構造を脳のニューロン構造から得ている、統計的に関数を近似するモデル
重要なので次章で詳しく説明します。