Amazon Bedrockについて
Amazon Bedrock は、Anthropic社の「Claude」、Meta社の「Llama」、Amazon自身の「Titan」をはじめとする、複数の主要な基盤モデルを利用できるサービスです。
APIを通じてこれらの基盤モデルにアクセスし、テキスト生成、要約、質疑応答(Q&A)、や画像生成といった機能をアプリケーションやサービスに組み込むことが可能です。
料金体系は従量課金制を採用しており、APIの呼び出しごとに料金が発生する仕組みとなっています。これにより、利用者は必要な分だけリソースを使用し、コストを最適化することができます。
モデルを比較モードで触ってみよう
利用することのできるモデルはリージョンによって異なります。まずは利用することのできるモデルの多いリージョンに移動して、様々なモデルを比較しながら触ってみましょう。
AWSのコンソールを開き、リージョンをバージニア北部(us-east-1)に移動してください。
検索バーにbedrockと入力し、Amazon Bedrockを選択、左のタブのプレイグラウンド > Chat/Textを選択し、いくつかのモデルを触ってみましょう。
プレイグラウンドを開いたら、右上の比較モードというトグルをONにして、複数のモデルを選択し、それぞれの回答を比較してみましょう。

パラメータの意味
モデルによって異なりますが、代表的なものとして以下のようなものがあります。
| パラメータ | 意味 |
| 温度 | ランダム性の強さ |
| トップP | 出力候補の中で、確率の合計がP以下になる単語の中から選ぶ |
| トップK | 出力候補の中で上位K個の中からランダムに選ぶ |
| 最大長 | 出力の最大トークン数 |
| 停止シーケンス | 出力を止めるキーワード |
質問例

リージョンを東京(ap-northeast-1)に戻しましょう。
RAGを用いたChatBotの作成
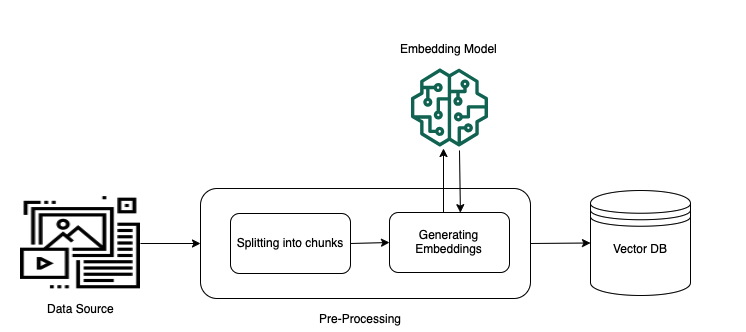
処理の流れと構成図
- 事前処理
テキスト文書のような非構造化データを検索できるようにするために以下のようなことを行います。
-
テキスト化と分割
データをテキストに変換し、扱いやすい小さなかたまり( チャンク )に分割します。
-
ベクトル化
各チャンクを ベクトル (数値の羅列)に変換します。
-
ベクトルインデックスへの保存
変換されたベクトルを ベクトルインデックス という場所に保存します。
これにより、質問(クエリ)が入力された際に、その質問もベクトルに変換し、データソースのベクトルとどれくらい似ているかを判断できるようになります。
これで、非構造化データから必要な情報を効率的に見つけ出すことができるようになります。
-
チャンキングについて
チャンキングの設定は文章をどう分割するかを決めるものです。
この設定によって、検索性の向上、ノイズとなる情報の除去が可能となります。
演習で今回出てくるチャンキングの設定(今回はデフォルトチャンキングを使用)。
チャンキング戦略 説明 デフォルトチャンキング テキストを約300トークンなど、事前定義されたトークン数(または文字数)で自動的に分割する。 固定サイズのチャンキング テキストを、固定トークン数(または文字数)で分割する。チャンク間にオーバーラップを設定することも可能。 階層型チャンキング テキストチャンク(ノード)を親子関係の階層構造に整理する。各子ノードは親ノードへの参照を持つ。 セマンティックチャンキング テキストチャンクや文のグループを、意味的な類似性や関連性に基づいて分割する。 チャンキングなし テキストをチャンクに分割せず、そのまま使用する。 - クエリの 実行時
質問が入力されてから回答が生成されるまでは以下のようなことを行っています。
-
質問のベクトル化
まず、あなたの質問(クエリ)を「埋め込みモデル」というものを使って ベクトル (数値の羅列)に変換します。
-
関連情報の検索
次に、この質問のベクトルと、事前に保存しておいたデータのベクトルを比較します。これにより、あなたの質問に意味的に関連性の高い情報のかたまり(チャンク)をデータベースから見つけ出します。
-
追加情報の付与
検索で見つかった関連性の高いチャンクを、あなたの元の質問に追加します。これにより、質問に追加のコンテキストが加わります。
-
回答の生成
最後に、追加のコンテキストが加わった質問をAIモデルに送ります。モデルはこの情報を使って、より正確で詳細な 回答を生成 します。
このように、RAG(Retrieval Augmented Generation)という仕組みを使うことで、AIは外部のデータソースから関連情報を引っ張ってきて回答を作り出すことができます。

それでは説明したような構成のものを作っていきましょう。
S3 バケットを作成しデータをアップロード
-
お渡ししたzipファイルを回答してください
💡本記事を読んでいる方は許可のあるwebページをスクレイピングするなどの方法でデータソースを用意してください。
- リージョンがアジアパシフィック(東京)になっていることを確認。
- ローカルでファイルを作成できたら、AWS コンソールで「S3」 → 「バケットを作成」を押し、適当な名前でそれ以外の設定を変更せずにバケットを作成してください。
- その後、作成したバケットを選択 > アップロードを押下し、解凍したhtmlファイルをアップロードしてください。
Bedrock ナレッジベース作成
-
Amazon Bedrock → 左のタブの「ナレッジベース」を選択 → 「作成」→ ベクトルストアを含むナレッジベースを選択。

- ナレッジベース名:適当なものを設定(デフォルトでも良い。)
-
IAM 許可
新しいサービスロールを作成して使用。
このとき作成されたサービスロールはお片付けの際に削除するのでメモしておきましょう。

-
データソースを選択:
S3(デフォルトでこうなっているはず。)
次へを押す。
データソース名: 適当なものを設定(デフォルトでも良い。)
S3 source: Browse S3から先程作成したs3を選択し、chooseを押下。
それ以外はデフォルトで次へ。
-
埋め込みモデル:
Titan Text Embeddings V2を選択
新しいベクトルストアをクイック作成 > ベクトルストア: Amazon OpenSearch Serverlessを選択

次へ > ナレッジベースを作成を押す。
数分かかり、ナレッジベースが作成される。

作成されたナレッジベースに飛び、ナレッジベースIDをメモ(後ほど使います)。

データソースをナレッジベースに同期
作成したナレッジベースへ移動して、

データソースを選択して右上の同期ボタンを押す。
数分かかるが、ナレッジベースにデータソースを反映させることができる。

Lambda 関数作成
-
コンソールからLambdaのページを開く → 左のタブの関数を選択 → 右上の関数を作成。

- 関数名:適当なものを設定
- ランタイム:Python3.13 を選択
-
デフォルトの実行ロールの変更のトグルを開く→ 既存のロールを使用する。→
LambdaBedrockKBRoleを指定。
こちらは講師が事前に準備しています。
関数の作成を押す。
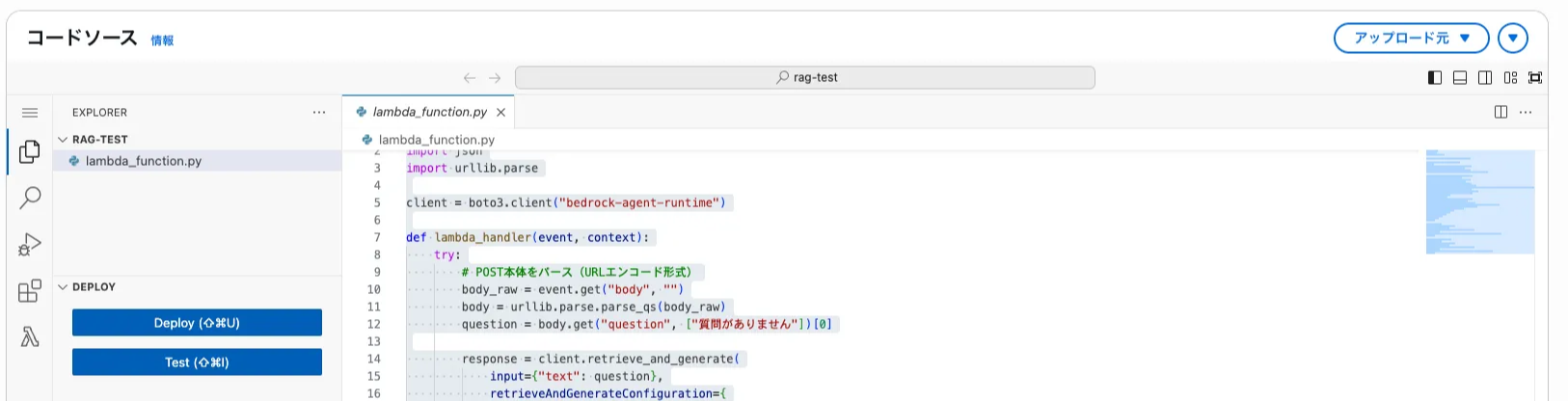
すると以下の画像のような画面に遷移するので、トグル内のコードを貼り付ける。
このとき、ナレッジベースのIDを先程メモしたものに変更する。
Lambda に貼り付けるコード
import boto3
import json
import urllib.parse
client = boto3.client("bedrock-agent-runtime")
def lambda_handler(event, context):
try:
# POST本体をJSONとしてパース
body_raw = event.get("body", "")
body = json.loads(body_raw)
question = body.get("question", "質問がありません")
response = client.retrieve_and_generate(
input={"text": question},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "XXXXXXXX",# 実際のIDに差し替え
"modelArn": "arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": 3
}
},
"generationConfiguration": {
"promptTemplate": {
"textPromptTemplate": (
"以下は参考情報です:\\n$search_results$\\n\\n"
"質問: {{query}}\\n\\n"
"答え:"
)
}
}
}
}
)
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps(response["output"]["text"], ensure_ascii=False)
}
except Exception as e:
return {
"statusCode": 500,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps({"error": str(e)}, ensure_ascii=False)
}
その後、画面左のDeployボタンを押してください。
タイムアウトの延長
- 設定タブの一般設定、右上の編集を押す。

-
タイムアウト:
1 分に変更。 - 「保存」ボタンをクリック。
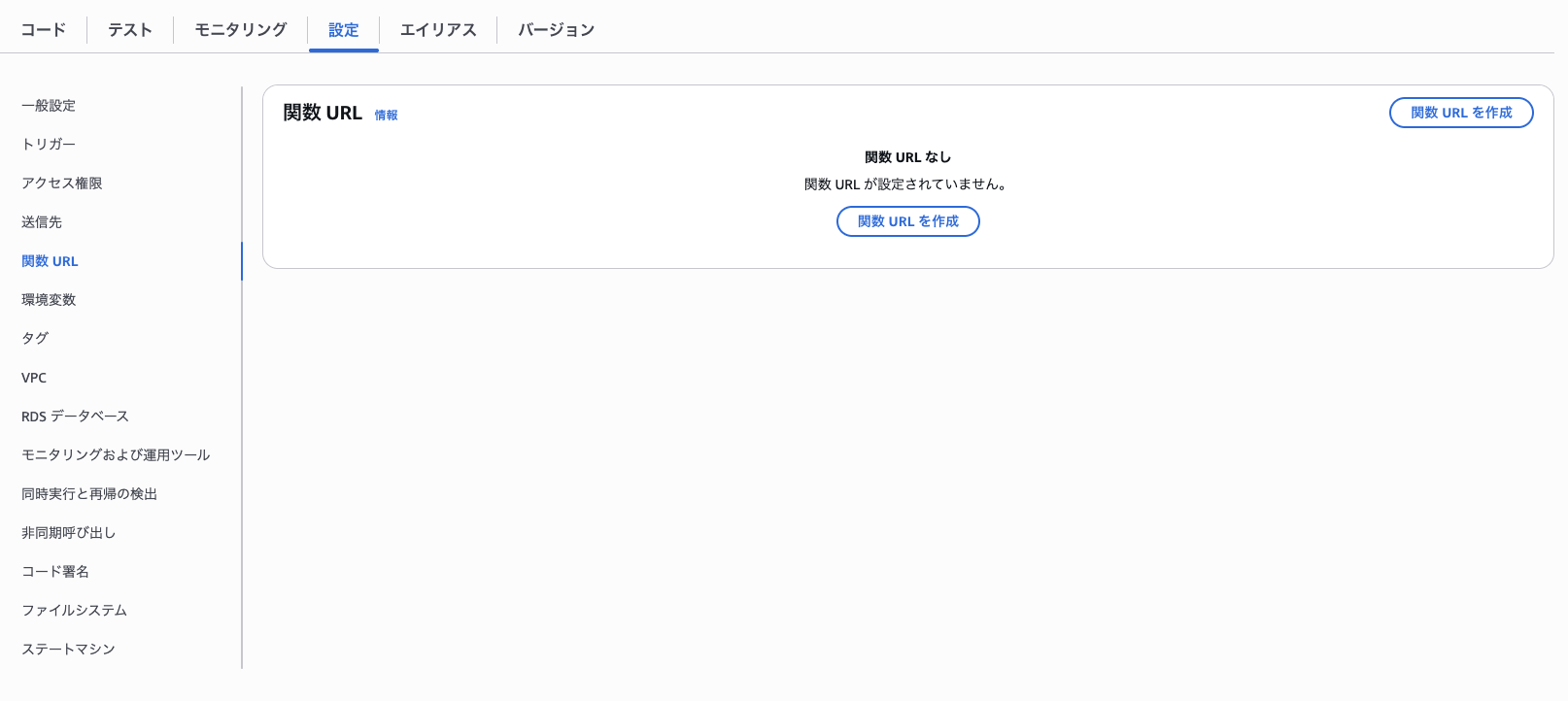
Lambda URL の作成
-
設定タブの関数URLを選択、右上の関数URLを作成を押す。
-
認証タイプ:
NONE 💡今回は演習のため、
💡今回は演習のため、NONEで設定しますが、Lambda関数を公開する場合は、認証・認可の仕組みを導入し、セキュリティを確保しましょう。 -
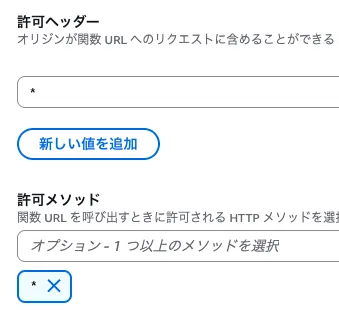
その他の設定のトグルを開く
オリジン間リソース共有 (CORS) を設定をチェック

許可ヘッダーと許可メソッドに
*
を入力(これでfileプロトコルからアクセス可能になる。)
「保存」ボタンをクリック
すると以下のように関数URLが作成されるのでURLをメモ
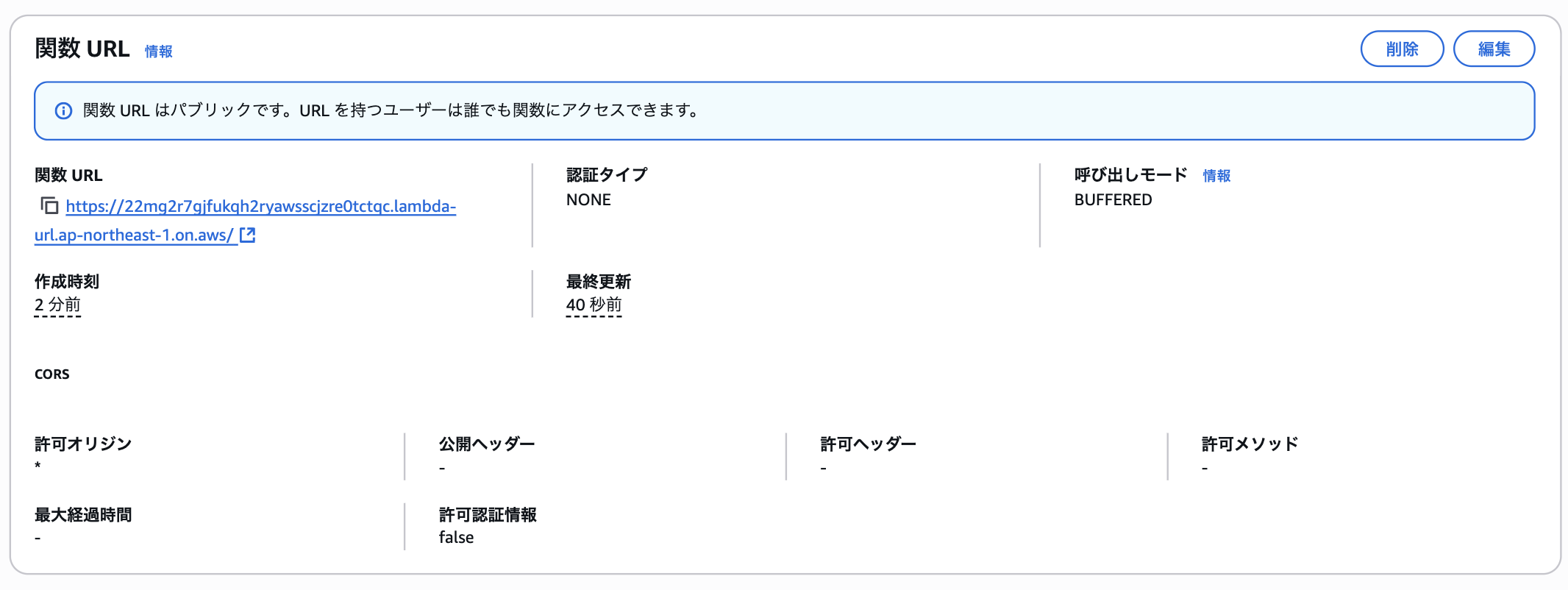
curl によるテスト
保存したURLに対してローカルから以下のようなリクエストを投げてみましょう。
同じ文章で複数回クエリを投げると同じ回答が返ってきてしまうので、キャッシュは無視してくださいという指示を追加しています。ただ、これでもキャッシュが無視されない可能性があります。
curl -X POST https://xxx.lambda-url.ap-northeast-1.on.aws/ -H "Content-Type: application/json" -d '{"question": "機動戦士Gundam GQuuuuuuX について知りたいです。キャッシュは無視してください"}'HTMLでテスト
以下のファイルをローカルに保存。
htmlファイルをwebブラウザーで開く。
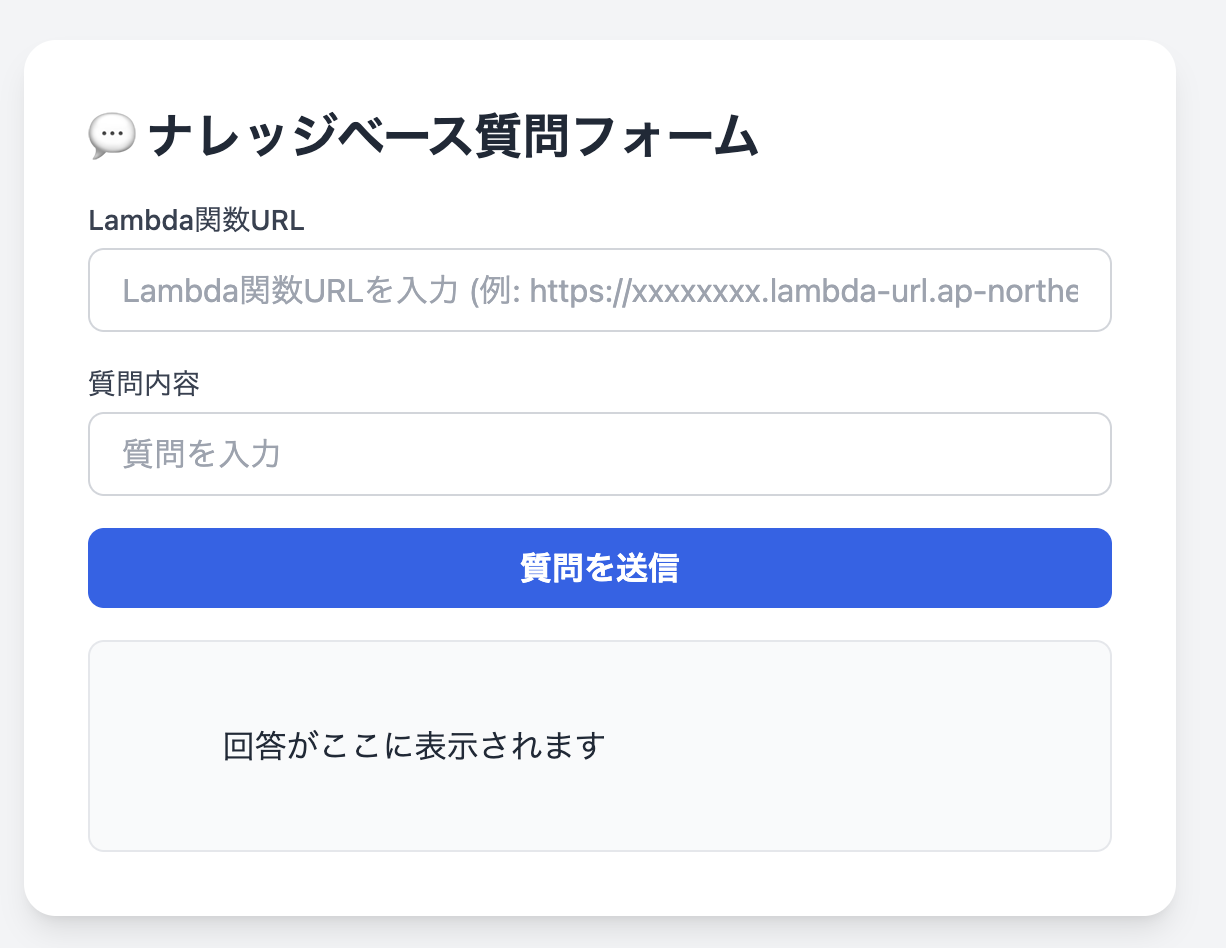
先ほどメモした関数URLと質問を入力すると、投入したデータソースをに基づいた回答を得ることができます。
時間が余った人向け:レスポンスを比較しよう
Lambdaのコードを書き換え、以下のHTMLからRAGと通常のLLMへのリクエスト時のレスポンスに違いが出ないことを確認しましょう。
Lambdaのコードを書き換えて以下のようにRAGと通常のLLMのレスポンスを比較してみましょう。
ヒント1
chat-compare.htmlが想定しているLambdaからのレスポンスは以下です。
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps({
"rag_answer": response["output"]["text"],
"llm_answer": response["output"]["text"]
}, ensure_ascii=False)
}ヒント3
AIに聞いてみよう
時間が余った人向け:ナレッジを追加してみよう
webサイトをpdfやhtmlの形式で保存してナレッジベースのナレッジを追加してみましょう。
作成したS3に保存したwebページのpdfなどの好きなドキュメントをアップロードして、ナレッジベースから自分の作成したナレッジベースへ移動し、以下の操作を再び実行しましょう。
ナレッジが追加され、その情報に基づいて質問に回答する用になるはずです。
📄
![]() 【生成AI 2025 #4】RAGを用いたChatBotの作成
【生成AI 2025 #4】RAGを用いたChatBotの作成